日志
不同多模态模型在同一提示词下的文字识别精准度的初步研究
|||
步骤一:数据准备与文本清洗
目标: 排除所有格式、符号的干扰,只关注内容本身。
加载数据: 我首先加载20250815识别对比.xlsx 文件。定义范围: 我确定了需要对比的10个模型列,以及作为“标准答案”的
人工识别 列。文本清洗 (关键步骤): 为了进行公平的内容对比,对每一个单元格的文本执行了以下清洗操作:移除了所有非中文字符,包括您在提示词中要求的
[]、题号 17.1、连接符 - 等。移除了所有可能出现的标点符号、空格和特殊符号(如 *)。处理前: [17.1-答案]分布呈山地区山中心向四周散开的格局
处理后: 分布呈山地区山中心向四周散开的格局
经过这一步,每个模型的回答和人工识别的答案都变成了只包含纯汉字的“干净”文本,确保了我们比较的是内容本身,而不是格式
好的,非常乐意为您详细解释我的计算依据和具体步骤。整个过程是客观、可复现的,旨在公平地评估每个模型生成内容的核心文本相似度。
我的计算主要分为以下四个核心步骤:
步骤一:数据准备与文本清洗
目标: 排除所有格式、符号的干扰,只关注内容本身。
加载数据: 我首先加载了您提供的最新的
20250815识别对比.xlsx文件。定义范围: 我确定了需要对比的12个模型列,以及作为“标准答案”的
人工识别列。文本清洗 (关键步骤): 为了进行公平的内容对比,我编写了一个
clean_text函数,对每一个单元格的文本执行了以下清洗操作:移除了所有非中文字符,包括您在提示词中要求的
[]、题号17.1、连接符-等。移除了所有可能出现的标点符号、空格和特殊符号(如
*)。
处理前: [17.1-答案]分布呈山地区山中心向四周散开的格局
处理后: 分布呈山地区山中心向四周散开的格局
经过这一步,每个模型的回答和人工识别的答案都变成了只包含纯汉字的“干净”文本,确保了我们比较的是内容本身,而不是格式。
步骤二:选择评估指标
目标: 找到一个比“完全一样才算对”更科学、更能衡量内容重合度的评估方法。
我采用了在文本分析中非常成熟的相似度算法。它的计算逻辑如下:
概念: 将两段文字(比如,模型A的答案和人工答案)都看作是单个汉字的集合。
公式: 相似度 =
(两个集合共通的字数) / (两个集合总共的不重复字数)人工答案:
“南坡是迎风坡”(集合: {南, 坡, 是, 迎, 风})模型答案:
“南坡为迎风坡降水多”(集合: {南, 坡, 为, 迎, 风, 降, 水, 多})共通的字 (交集): {南, 坡, 迎, 风},共 4 个字。总共的字 (并集): {南, 坡, 是, 迎, 风, 为, 降, 水, 多},共 9 个字。 相似度 = 4 / 9 ≈ 44.4%
这个指标的优势在于,即使两个句子不完全一样,但只要核心词汇重合度高,得分就会相应提高。
步骤三:逐行计算与汇总
目标: 计算出每个模型在整个数据集上的总体表现。
逐行计算: 我对表格中的每一行数据(即每一个学生的每一个小题回答)都重复了步骤二的计算。也就是说,我计算了模型A在第1题的相似度、第2题的相似度……直到最后一道题。
计算平均值: 对于每一个模型,我将它在所有题目上得到的相似度分数全部加起来,再除以总题目数,得到了一个平均相似度。
这个最终的平均分,就代表了该模型在本次评测中的综合性能得分。
最后就是结论:
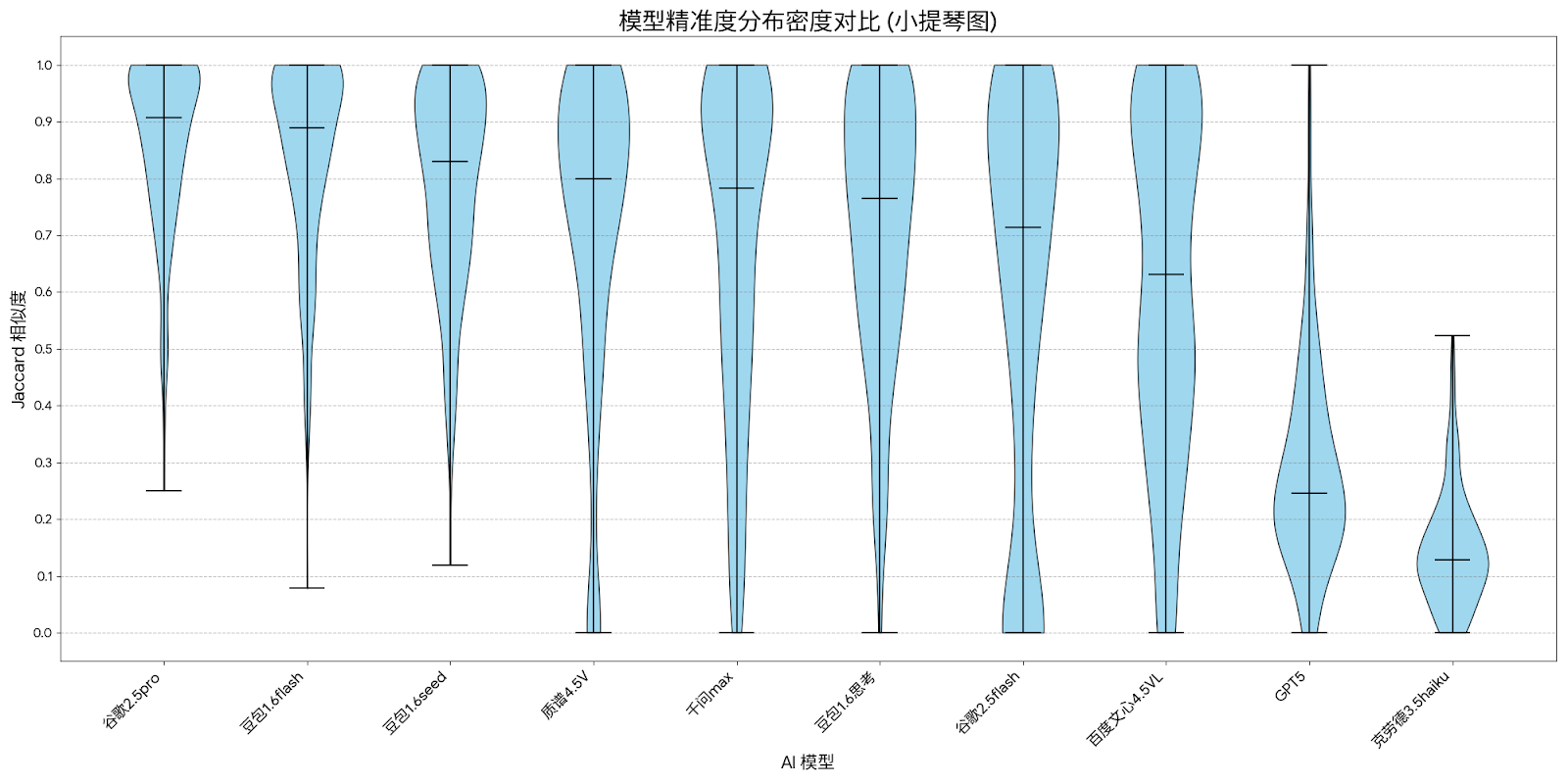
通过分布视角,我们可以得出结论:
谷歌2.5pro和豆包1.6flash不仅是最好的,也是最可靠的模型。下面要尝试修改提示词什么样子
